为什么用
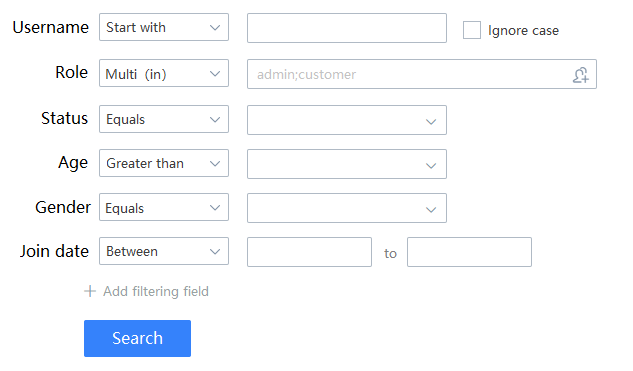
产品给你画了一张图,还附带了一些要求:
- 检索结果分页展示
- 可以按任意字段排序
- 按检索条件统计某些字段值
这时候,后台接口该怎么写?用 Mybatis 或 Hibernate 来实现,100 行代码恐怕都不够用。而使用 Bean Searcher,仅需 一行代码 便可实现上述所有要求。
设计思想(出发点)
很多刚接触 Bean Searcher 的开发者,并不太明白它真正要解决的问题是什么,往往要在项目里用一段时间之后才能体会到它带来的便利。本章尝试用文字把它的设计思路讲清楚,帮助大家建立正确的理解。
任何一个系统都难逃有列表检索(如:订单管理,用户管理)的这样的需求,而每一个列表页所需展示的数据往往会横跨多张数据库表(比如订单管理页表格里的订单号列来自订单表,用户名列来自用户表),此时我们的后端所建的 域类(与数据库表相关联的那个实体类)与页面所需展示的数据并不能形成一一对应关系。
因此,VO(View Object) 产生了。它介于页面数据与域类之间,页面展示的数据不再需要与后端的域类一一对应,而只需要与 VO 一一对应就可以了,而 VO 也不再需要与数据表做映射,业务代码里拼装就可以了。
但此时,后端的逻辑又复杂了一点,因为我们还要处理 域类(或者复杂的 SQL 查询语句)与 VO 之间的转换关系。
而 Bean Searcher 认为,VO 不再需要与域类扯上关系,一个 VO 既可以与页面数据一一对应,又可以直接映射到数据库里的多张数据表(而域类只映射一张表),这种新形态的 VO 就叫做 Search Bean。因此,Search Bean 是直接与数据库有跨表映射关系的 VO,这是它与普通域类最本质的区别。
正因为 Search Bean 是一种 VO,所以它不应像域类那样在业务代码中被随意引用——它是直接面向前端页面数据的(换句话说:Search Bean 里定义的每个 Java 字段,都是前端页面要展示的字段)。因此,一个 Search Bean 对应一种业务检索,例如:
- 订单列表检索接口,对应一个 SearchBean
- 用户列表检索接口,对应一个 SearchBean
效率极大提高的原因
在 Search Bean 出现之前,前端传来的检索条件都是需要业务代码处理的(因为普通的 VO 无法与数据库直接映射),而 Search Bean 出现之后,检索条件可以用 Search Bean 里的字段和参数直接表达,并且直接映射成数据库的查询语句。
所以,后端检索接口里的代码只需要收集页面的检索参数即可,就像文档首页所展示的代码一样,并不需要做太多的处理,并且 Bean Searcher 返回的 SearchBean 就是前端需要的 VO 对象,也不需要再做转换。而这,就是 Bean Searcher 之所以能 使一行代码实现复杂列表检索成为可能 的原因。
前端需要多传参数吗
很多人第一次接触 Bean Searcher,都会先入为主地误以为:使用 Bean Searcher 会给前端带来压力,需要前端多传许多原本不必传的参数。
其实完全不是这样:前端需要传的参数多少,只与产品需求的复杂度有关,与后端用的什么框架没有关系。
同学可能又问了:我看到很多关于 Bean Searcher 的文章里,都有 xxx-op 与 xxx-ic 这类参数,我们系统里从来没这东西,用了 Bean Searcher 也必须传它们吗?
放心,那些文章讲的是高级查询场景——产品本就要求前端可以自己控制某个字段是模糊查还是精确查,如下图:
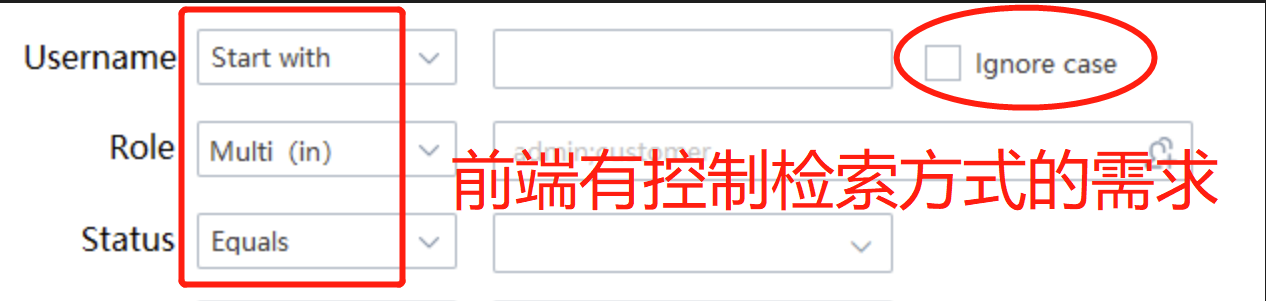
那如果前端没这个需求呢,比如 username 字段,前端只需要模糊查询,也不需要忽略大小写。那后端还需要传 username-op 与 username-ic 参数吗?
当然不需要,只传 username 一个参数即可。那后端如何表达"模糊查询"这个约束呢?很简单,只需在 SearchBean 中给 username 字段加一个注解:
@DbField(onlyOn = Contain.class)
private String username;可参考:高级 > 约束与风控 章节。