Bean Searcher
Bean Searcher 是一个 Java 声明式检索框架 — 实体定义检索边界,参数驱动查询逻辑。单表零注解即可搜,一行代码即可完成分页、筛选、排序、统计、多表联查。
不依赖具体的 Web 框架(可在任意 Java Web 框架中使用)
不依赖具体的 ORM 框架(可与任意 ORM 配合使用,也可单独使用)
架构设计图
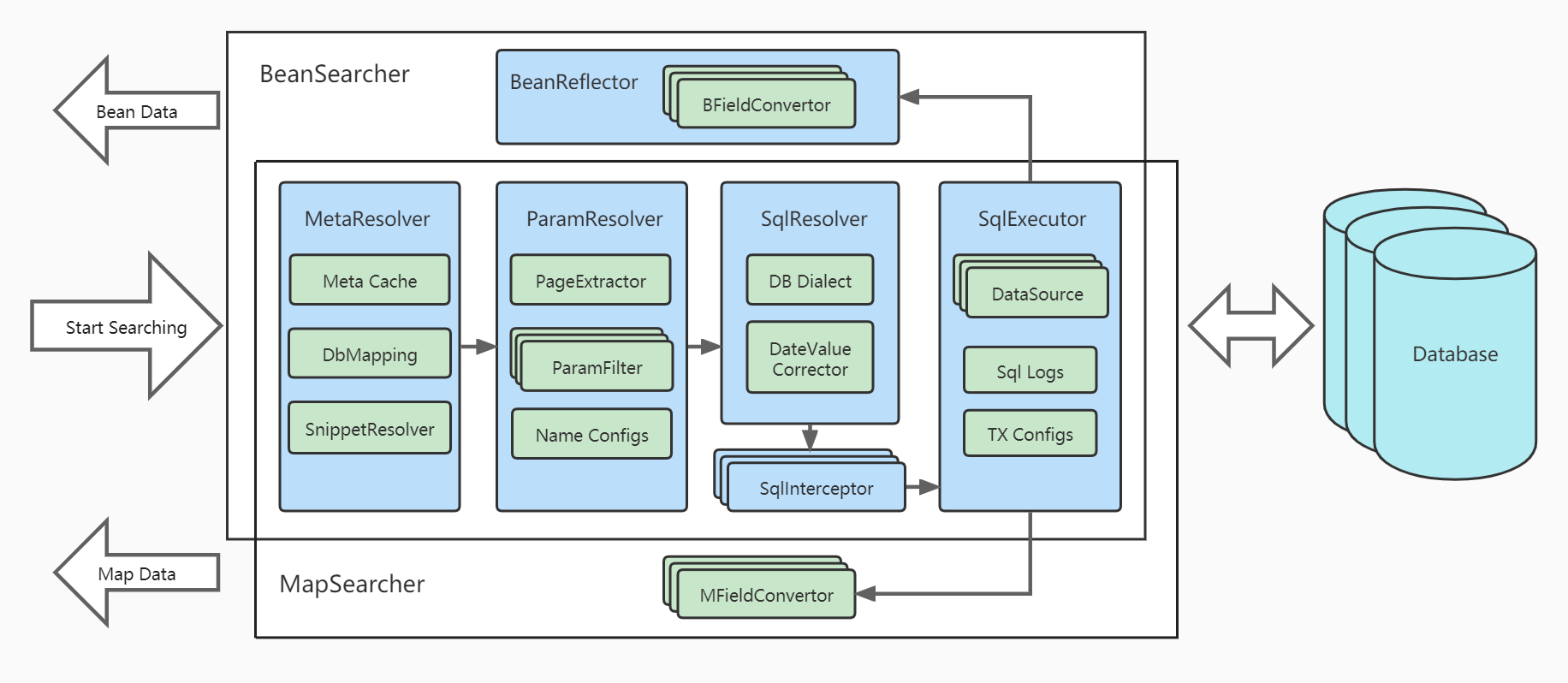
一句话理解:列表检索领域的 GraphQL
如果你了解 GraphQL,理解 Bean Searcher 只需要一句话:
GraphQL 让客户端在一次请求中自由指定要什么字段;Bean Searcher 让客户端在一次请求中自由指定要什么字段、按什么条件筛选、按什么字段排序。
不同的是,GraphQL 需要专用协议和 schema,Bean Searcher 工作在标准 HTTP 参数上——GET、POST、表单提交,协议无关,零迁移成本。
| GraphQL | Bean Searcher | |
|---|---|---|
| 领域 | API 数据查询 | 数据库列表检索 |
| 客户端控制 | 指定返回字段 | 指定返回字段 + 筛选条件 + 排序规则 + 分页 |
| 协议 | POST + GraphQL body | 标准 HTTP 参数(不挑 method) |
| 核心思想 | 声明你想要什么 | 实体定义边界,参数驱动查询 |
| 接入成本 | 需要改 API 层 | 加一个依赖即可 |
就像 GraphQL 用一次请求替代多次 REST 调用,Bean Searcher 用一行 search() 替代层层 if-else 条件拼接。
与 MyBatis / Hibernate 的关系
首先,Bean Searcher 不是 ORM 框架,它存在的目的不是为了替换 MyBatis 或 Hibernate,而是为了弥补它们在 列表检索领域 的不足——正如 GraphQL 不是为了替换 REST,而是在查询场景提供更强的灵活性。
下表列举它们之间的具体区别:
| 区别点 | Bean Searcher | Hibernate | MyBatis |
|---|---|---|---|
| 定位 | 声明式检索框架 | 全自动 ORM | 半自动 ORM |
| 实体类可多表映射 | 支持 | 不支持 | 不支持 |
| 字段运算符 | 动态(客户端驱动) | 静态 | 静态 |
| CRUD | 只读(R) | CRUD | CRUD |
| 与 ORM 关系 | 互补共存 | — | — |
从上表可以看出,Bean Searcher 只能做数据库查询,不支持增删改。但它的多表映射机制与动态字段运算符,让复杂列表检索的代码量可以缩减到原来的十分之一,甚至百分之一。
更关键的是,它没有第三方依赖,在项目中可以和任意 ORM 配合使用。
哪些项目可以使用
Java 项目(当然 Kotlin、Groovy 也是可以的);
使用了 关系数据库的项目(如:MySQL、Oracle 等);
可与任意框架集成:Spring Boot、Grails、Jfinal 等等。
什么场景下需要用
任何框架都有其使用场景,当然 Bean Searcher 也不例外,它的诞生并不是为了替换 MyBatis / Hibernate 等传统 ORM,因此,理解哪些场景适合使用它非常重要。
推荐 在 非事务性 的 动态 检索场景中使用,例如:
管理后台的 [订单管理]、[用户管理] 等页面 的检索场景,该检索是 非事务性 的,不会向数据库中插入数据,且检索条件是 动态 的,用户检索方式不同,执行的 SQL 也不同(如按
订单号检索 与 按状态检索 需要不同的 SQL),此时推荐使用 Bean Searcher 来执行检索;不建议 在 事务性 的 静态 查询场景中使用,例如:
用户注册接口中需要先查询账号是否已存在的场景,该接口是 事务性 的,它需要向数据库中插入数据,且此时的查询条件是 静态 的,无论哪个账号,都执行一样的 SQL(都按
账号名查询),此时不建议使用 Bean Searcher 来执行。
支持哪些数据库
只要支持正常的 SQL 语法,都是支持的,另外 Bean Searcher 内置了五个方言实现:
- 分页语法和 MySQL 一样的数据库,默认支持
- 分页语法和 PostgreSQL 一样的数据库,选用 PostgreSQL 方言 即可
- 分页语法和 Oracle 一样的数据库,选用 Oracle 方言 即可
- 分页语法和 SqlServer (v2012+) 一样的数据库,选用 SqlServer 方言 即可
- 分页语法和 达梦 一样的数据库,选用 DaMeng 方言 即可
如果分页语法是独创的,自定义一个方言即可,只需实现两个方法,参考:高级 > SQL 方言 章节。
🚀 在线体验
无需部署,即刻感受声明式检索:在线 Demo