Why Use It
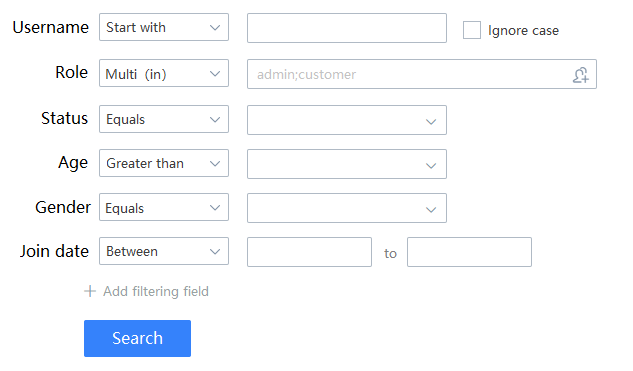
The product manager has drawn a diagram for you and attached some requirements:
- Display search results in pages.
- Sort by any field.
- Count certain field values according to search criteria.
At this time, how should the backend api be written? Would it take more than 100 lines of code if you use MyBatis or Hibernate? However, with Bean Searcher, you can achieve the above requirements with just one line of code!
Design Concept
This section is written mainly because many people who are new to Bean Searcher don't quite understand what problems it really solves. Only after using it correctly for some time can they experience the great convenience it brings. This chapter attempts to show you some of its design considerations in words.
Any system inevitably has requirements for list retrieval (e.g., order management, user management). The data to be displayed on each list page often spans multiple database tables. For example, in the order management page table, the order number column comes from the order table, and the user name column comes from the user table. At this time, the domain classes (the entity classes associated with database tables) created by our backend do not correspond one-to-one with the data to be displayed on the page.
Therefore, VO (View Object) was created. It lies between the page data and the domain classes. The data displayed on the page no longer needs to correspond one-to-one with the backend domain classes, but only needs to correspond one-to-one with the VO. And the VO no longer needs to be mapped to the data tables; it can be assembled in the business code.
However, at this time, the backend logic becomes a bit more complex because we also need to handle the conversion relationship between the domain classes (or complex SQL query statements) and the VO.
Bean Searcher believes that the VO no longer needs to be related to the domain classes. A VO can not only correspond one-to-one with the page data but also be directly mapped to multiple database tables (unlike domain classes, which are only mapped to one table). This new type of VO is called a Search Bean. Therefore, a Search Bean is a VO that has a cross-table mapping relationship with the database directly, and it is fundamentally different from the domain classes.
Since a Search Bean is a type of VO, it should not be casually referenced in the business code like a domain class. It is directly oriented to the page data of the front end. (Understand deeply: the Java fields defined in a Search Bean are directly used by the front-end pages.) Therefore, a Search Bean represents a type of business retrieval, such as:
- The order list retrieval interface corresponds to a SearchBean.
- The user list retrieval interface corresponds to a SearchBean.
Why Great Improvement in Efficiency
Before the emergence of Search Beans, the retrieval conditions sent from the front end needed to be processed by the business code (because ordinary VOs cannot be directly mapped to the database). After the emergence of Search Beans, the retrieval conditions can be directly expressed using the fields and parameters in the Search Bean and directly mapped to database query statements.
Therefore, the code in the backend retrieval interface only needs to collect the retrieval parameters from the page, just like the code shown on the documentation homepage. It doesn't need to do much processing. Moreover, the SearchBean returned by Bean Searcher is the VO object needed by the front end, and there is no need for further conversion. This is why Bean Searcher makes it possible to implement complex list retrieval with one line of code.
Does the Front-end Need to Pass More Parameters?
Many people who are new to Bean Searcher will, preconceivedly, misthink that using Bean Searcher will put pressure on the front end and require the front end to pass many parameters that it didn't need to pass originally.
Actually, it's not the case. The number of parameters that the front end needs to pass is only related to the complexity of the product requirements and has nothing to do with the backend framework used.
Some students may ask: I've seen many articles about Bean Searcher that mention parameters like xxx-op and xxx-ic. There are no such parameters in our system. Do we need to pass them after using Bean Searcher?
Well, students should note that the content in those articles is about advanced queries. The product requires the front end to be able to control whether a certain field is searched by fuzzy matching or exact matching, as shown in the following figure:
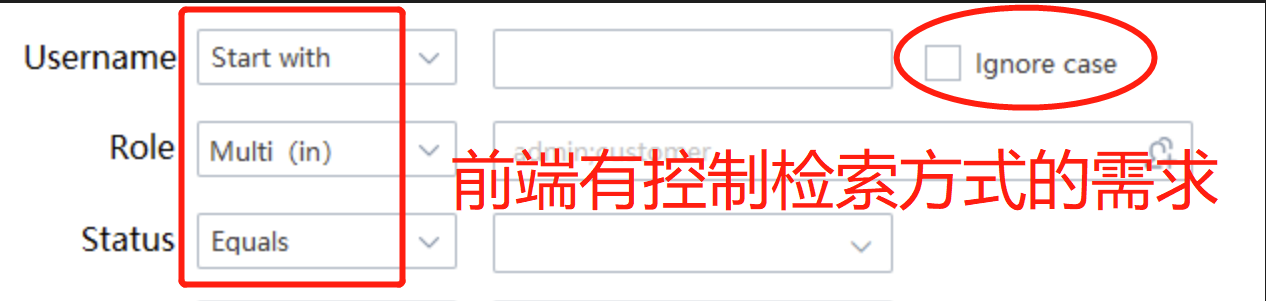
What if the front end doesn't have this requirement? For example, for the username field, the front end only needs a fuzzy query and doesn't need to ignore case. Do we still need to pass the username-op and username-ic parameters in the backend?
Of course not. We only need to pass the username parameter. So how does the backend express the fuzzy query condition? It's very simple. Just add an annotation to the username attribute in the SearchBean:
@DbField(onlyOn = Contain.class)
private String username;You can refer to the Advanced > Constraints and Risk Control section.