Bean Searcher
Bean Searcher is a Java declarative search framework — entities define search boundaries, parameters drive query logic. Single-table entities are searchable with zero annotations. One line of code handles pagination, filtering, sorting, stats, and multi-table joins.
- It does not depend on a specific Web framework (i.e., it can be used in any Java Web framework).
- It does not depend on a specific ORM framework (i.e., it can be used in conjunction with any ORM framework and can also be used independently without an ORM).
Architecture Design Diagram
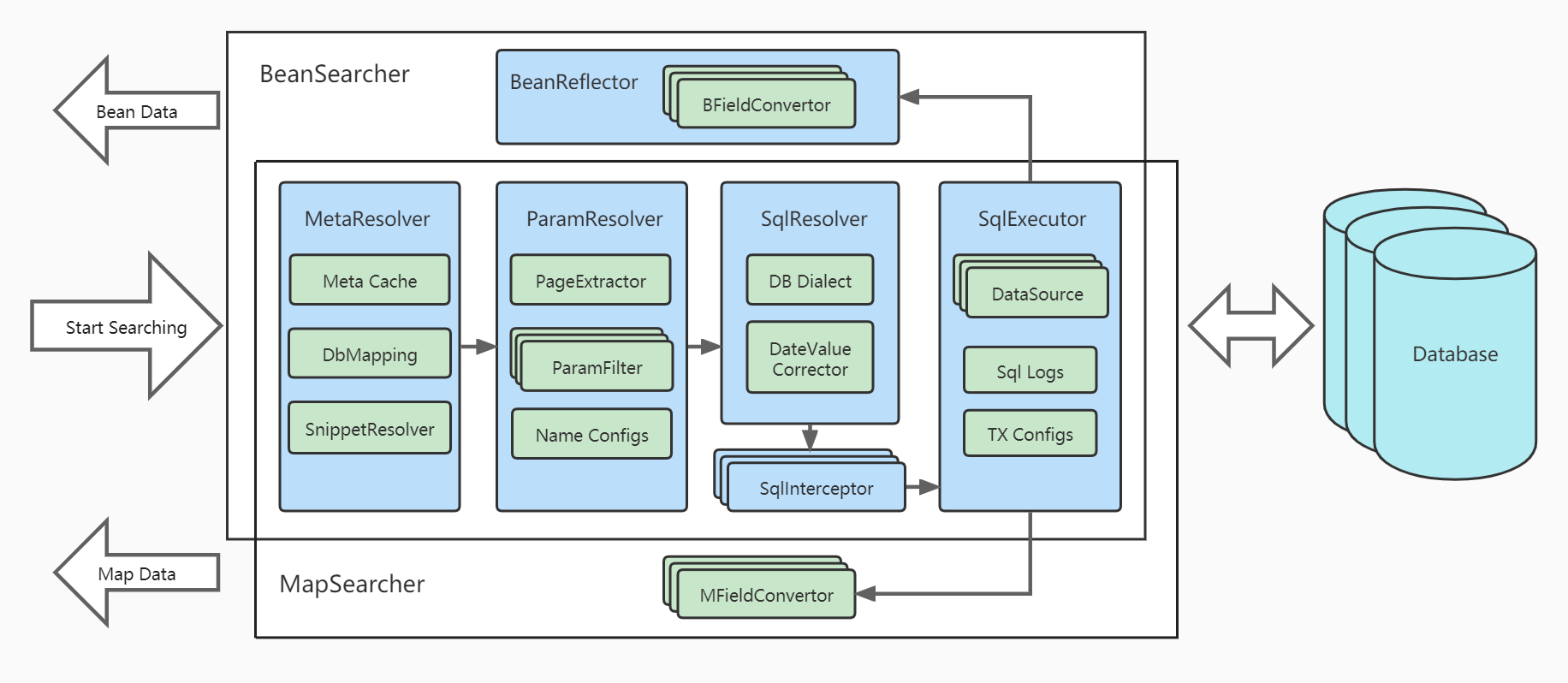
Understanding in One Sentence: The GraphQL of List Retrieval
If you know GraphQL, understanding Bean Searcher takes one sentence:
GraphQL lets clients freely specify which fields to return in one request; Bean Searcher lets clients freely specify which fields to return, which conditions to filter by, and which fields to sort by — all in one request.
The difference: GraphQL requires a dedicated protocol and schema; Bean Searcher works on standard HTTP parameters — GET, POST, form submissions, protocol-agnostic, zero migration cost.
| GraphQL | Bean Searcher | |
|---|---|---|
| Domain | API data queries | Database list retrieval |
| Client control | Specifies return fields | Specifies return fields + filter conditions + sort rules + pagination |
| Protocol | POST + GraphQL body | Standard HTTP parameters (any method) |
| Core idea | Declare what you want | Entities define boundaries, parameters drive queries |
| Adoption cost | Requires API layer changes | Add one dependency |
Just as GraphQL replaces multiple REST calls with one query, Bean Searcher replaces layers of if-else condition stitching with one search() call.
Relationship with MyBatis / Hibernate
First of all, Bean Searcher is not an ORM framework. Its purpose is not to replace MyBatis or Hibernate but to fill the gap they leave in the list retrieval field — just as GraphQL isn't meant to replace REST, but to offer greater flexibility in query scenarios.
The following table lists the specific differences between them:
| Difference Point | Bean Searcher | Hibernate | MyBatis |
|---|---|---|---|
| Positioning | Declarative Search Framework | Fully automatic ORM | Semi-automatic ORM |
| Entity classes can be mapped to multiple tables | Supported | Not supported | Not supported |
| Field operators | Dynamic (client-driven) | Static | Static |
| CRUD | Read-only (R) | CRUD | CRUD |
| Relationship with ORM | Complementary coexistence | — | — |
As shown in the table above, Bean Searcher only supports database queries — it does not handle insert, update, or delete operations. However, its multi-table mapping mechanism and dynamic field operators can make our code ten times more efficient, or even a hundred times more efficient when performing complex list retrievals.
More importantly, it has no third-party dependencies and can be used in conjunction with any ORM in the project.
Which projects can use it
- Java projects (Kotlin and Gradle projects are also supported);
- Projects that use relational databases (e.g., MySQL, Oracle, etc.);
- It can be integrated with any framework: Spring Boot, Grails, JFinal, etc.
When to use it
Every framework has its use cases, and Bean Searcher is no exception. It is not meant to replace traditional ORMs such as MyBatis or Hibernate. Understanding which scenarios suit it best is essential.
- Recommended for non-transactional and dynamic retrieval scenarios. For example: Take the [Order Management] and [User Management] screens in an admin panel. These retrieval scenarios are non-transactional — they only query data, never inserting into the database. The search conditions are dynamic — different filters (e.g., by order number vs. by status) produce different SQL statements. This is where Bean Searcher excels.
- Not recommended for transactional and static query scenarios. For example: In a user registration endpoint, the interface first checks whether an account already exists. This is a transactional operation because it inserts data into the database. The query condition is static — regardless of the account, the same SQL is executed (filtering by account name). In this case, Bean Searcher is not the right tool.
Which databases are supported
As long as a database supports normal SQL syntax, it is supported. In addition, Bean Searcher has five built-in dialect implementations:
- Databases with the same pagination syntax as MySQL are supported by default.
- For databases with the same pagination syntax as PostgreSQL, select the PostgreSQL dialect.
- For databases with the same pagination syntax as Oracle, select the Oracle dialect.
- For databases with the same pagination syntax as SqlServer (v2012+), select the SqlServer dialect.
- For databases with the same pagination syntax as DaMeng, select the DaMeng dialect (since v4.6.0).
If a database has a unique pagination syntax, you only need to customize a dialect by implementing two methods. Refer to the Advanced > SQL Dialect section.
🚀 Live Demo
Try declarative search without deployment: Live Demo